Pod是Kubernetes集群中的最小调度单元。举例来说,Kubernetes是整个公司,定义了一系列的规章制度(功能),而公司是由人构成的,去进行工作,也就是说,人是公司中的最小调度单元,Pod亦是如此:人的工作是写文档,做表格等;Pod的工作是管理运行应用程序(容器化)。
Pod是一个或多个容器的集合。好比:Pod是一个快递盒子,应用就被打包放在了这个盒子里,在其中它们共享网络和存储资源。
写在前面
继上一篇的《一键搞定!Kubernetes1.29.6高可用部署指南,老少皆宜》,能够构建起一个单Master/多Master的Kubernetes集群,也了解了集群的构成等基础知识。本着后面写一些基础的Kubernetes概念性文章,例如控制器等,但官网已经解释很明白了,有比自己做的更好的,自己就不去再做了,写一些自己比较摸棱两可的,梳理一番。本文将探讨:Service,Endpoints,EndpointSlices,无头Service,有/无状态服务。
Pod访问问题
想象一下,你有一个博客项目:
1. 在传统模式下:
需要将Blog博客项目部署到一台安装了Apache服务的服务器上,用户通过在浏览器上,输入该服务器的IP地址/域名:端口(如: 192.168.10.100:8080)来访问博客页面。
2. 在Kubernetes下:
Blog博客项目被打包到 Pod中运行。你的博客现在被运行在Pod中,而不是直接运行在服务器上。
那么此时访问Pod中的Blog项目,再像传统模式一样,通过Pod的IP:Port,是不行的。原因如下:
隔离性:Pod使用容器技术,与宿主机(运行Pod的实际服务器)网络是隔离的。
不稳定性:Pod可能会被销毁和重新创建,每次IP地址都可能改变。
端口冲突:在传统服务器上,不同应用必须使用不同的端口。但在Kubernetes中,不同Pod可以使用相同的端口,因为它们是隔离的。如果多个Blog的Pod,端口都一样,怎么知道访问就是自己的呢。
为了应对这一问题,在Kubernetes容器管理平台上,单独有了一个角色,就是为了将运行在一个或一组 Pod 中的应用程序公开到网络的方法:即Service。
也就是说,Service是流量访问的入口/网关。
Endpoints与EndpointSlices
再介绍Service之前,先来说一下Endpoints,以及它的改进版:EndpointSlices。
Endponints,翻译过来叫端点,同Service创建而自动创建,与Service同名。它的作用是:
记录Service关联的后端Pod的IP地址和端口的集合。动态更新,当Service关联的后端Pod,删除,增加,更新了,Endpoints的地址记录也会被更新。
借此,我们不需要关心Pod若被删除,或者IP地址更改而带来的寻址不到的问题。
借用官网的例子: [1]
我们可以在创建一个Service,并将其关联到后端的Pod之后,查看Endpoints的信息:
# kubectl get endpoints nginx-service
NAME ENDPOINTS AGE
nginx-service 10.244.0.5:80,10.244.0.6:80,10.244.0.7:80 1m
EndpointSlices,是Endpoints的改进版本,同Service创建而自动创建,与Service同名。它的作用是:
- 提供与
Endpoints相同的基本功能。 - 支持更高效的
Endpoints信息的更新和扩展。
我们可以再创建一个Service,并将其关联到后端的Pod之后,查看EndpointSlices的信息:
# kubectl get endpointslices -l kubernetes.io/service-name=nginx-service
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
nginx-service-abc12 IPv4 80 10.244.0.5,10.244.0.6 2m
nginx-service-def34 IPv4 80 10.244.0.7 2m
对比Endpoints 和 EndpointSlices的输出信息,我们可以发现:
EndpointsSlices将 ENDPOINTS列的信息 由之前的一个,切割划分成为了多个,这样做的优势是:
- 在我们的例子中,只有 3 个 Pod,端点信息的存储值也就3个IP,信息量不大。enpointSlices与endpoint的差异不大。
- 但如果是100个或1000个Pod的情况,如果使用Endpoints,端口信息的存储值会成百上千,如下面所示:
# kubectl get endpoints nginx-service
NAME ENDPOINTS AGE
nginx-service Pod-1的IP:Port, ... , Pod-1000的IP:Port 1m
这样管理起来会很臃肿,麻烦,低效,也消耗集群的资源:假如其中的一个Pod信息发生了改变,则需要更新整个Endpoints;
但如果使用EndpointSlices,因为它把一个端点信息划分成多个,可以更高效地更新和管理这些信息。同样是更新一个Pod信息,就不需要更新整个Endpoints,只需要更新Pod所在的其中一个EndpointSlices即可。
总结Endpoints:
- 单个大对象包含所有端点信息。
- 通常需要整体更新。
- 在大规模部署中可能面临性能瓶颈。
- 较早引入,广泛支持。
- 最多包含1000个端点。
总结EndpointSlices:
分片存储:端点信息被分割成多个较小的 EndpointSlice 对象。
高效更新:可以只更新变化的部分,而不是整个列表。
增强的元数据:包含额外信息,如拓扑数据,有助于更智能的路由决策。
更好的性能:设计用于处理大规模集群和服务。
一个 Service 可以链接到多个 EndpointSlice 之上
默认情况下,一旦现有 EndpointSlice 都包含至少 100 个端点,Kubernetes 就会创建一个新的 EndpointSlice。
Kubernetes官方推荐使用 EndpointSlice API(Kubernetes v1.21 [stable]) 替换 Endpoints。
Service概述
创建一个Service,并与后端的Pod关联起来并不难。先看实践:
# 创建名为my-nginx的Service,并关联集群中带有run:my-nginx的pod。
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
$ kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s
$ kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.0.162.149
IPs: 10.0.162.149
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.5:80,10.244.3.4:80
Session Affinity: None
Events: <none>
$ kubectl get endpointslices -l kubernetes.io/service-name=my-nginx
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
my-nginx-7vzhx IPv4 80 10.244.2.5,10.244.3.4 21s
Service:my-nginx被创建,查看endpointslices信息也都正确。此时在节点上访问IP:10.0.162.149,能够访问到Nginx的首页。
实践操作很简单,映射到底层的样貌,如下图所示;
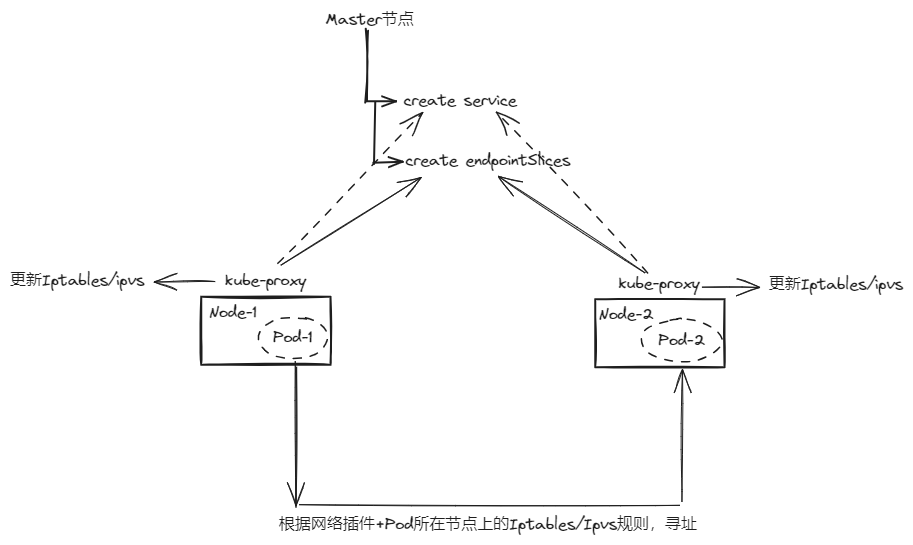
- Master节点上,管理员通过
kubectl命令等方式,创建Service,同时,自动创建同名的Endpoints/EndpointSlices,存储后端的Pod信息。 - 至此Service和EndpointSlices的使命已经结束,只是创建出一些数据而已。
- 每个节点上都由一个Kube-Proxy的组件,它的职责:定期监视
Service和EndpointSlices的数据信息是否更新,删除,创建等,并自动创建/更新每个节点上的Iptables/Ipvs规则。 - 之后,Pod间的通信,或者外部的通信访问,都是通过节点的Iptables规则/Ipvs配置来将数据包进行转发,传输。若是跨节点的Pod通信,则还需要借助网络插件来实现,例如Flannel/Calico等。
由上述,我们得知Service本事只是创建一组元数据罢了,实际做流量转发的是节点上的规则。那么规则的创建进而可以通过创建Service的类型不同,而不同。
Service类型
要控制kube-proxy所创建的iptables规则/ipvs配置,可以通过修改Service的类型去控制。
默认Service有四种类型,分别是:
- ClusterIP(默认类型)
- 特点:分配一个集群内部的 IP 地址,仅在集群内部可访问。例如Pod和Pod之间的通信,如果是Kubernetes集群外的请求访问是不行的。
- NodePort
特点:宿主机上开启一个特定端口(默认范围 30000-32767),直接与Pod的端口相连,实现访问宿主机IP:端口能够直接访问到Pod。用途:允许外部访问,但通常用于开发或测试。
适用场景:简单的外部访问需求,如演示或临时访问。
- LoadBalancer
特点:使用云提供商的负载均衡器暴露服务,创建外部的负载均衡器,将流量分发到后端Pod上,即该类型的Service本身的负载均衡是与外部的负载均衡服务关联,实现。创建该类型的Service的原因也是创建一堆数据,进而外部的负载均衡器根据这些数据,创建负载调度规则,再结合kube-proxy实现流量接入:外部客户端 -> 云负载均衡器 -> Kubernetes 节点 -> kube-proxy -> Pod。
适用场景:生产环境中需要高可用和负载均衡的外部服务。
- ExternalName
特点:将外部服务映射到集群内部,并以DNS的形式用于Pod中服务对外部服务访问。
适用场景:集成外部服务,如数据库或 API端点。
具体创建方式,可以查询官网: [1]
Service的负载均衡
Service实现负载均衡的方式有两种:iptables 和 ipvs。
Iptables模式:kube-proxy 在 Linux 上使用 iptables 配置数据包转发规则的一种模式。
因此,该模式下流量的负载均衡,是由iptables规则来实现的。
验证:
# 使用yaml部署测试Pod,Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
namespace: week
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: week
spec:
selector:
app: nginx
ports:
- name: nginx
protocol: TCP
port: 80
targetPort: 80
# 查看
[root@k8s-mn01 ~]# kubectl get pod -n week
NAME READY STATUS RESTARTS AGE
nginx-54b6f7ddf9-4jt5r 1/1 Running 0 8m5s
nginx-54b6f7ddf9-6stvj 1/1 Running 0 8m5s
nginx-54b6f7ddf9-kr2vn 1/1 Running 0 8m5s
[root@k8s-mn01 ~]# kubectl get svc -n week
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc ClusterIP 172.16.73.164 <none> 80/TCP 9m27s
# 去到任意一个工作节点上,过滤出相对应的iptables条目
[root@k8s-wn01 ~]# iptables-save | grep 172.16.73.164
-A KUBE-SERVICES -d 172.16.73.164/32 -p tcp -m comment --comment "week/nginx-svc:nginx cluster IP" -m tcp --dport 80 -j KUBE-SVC-4LRRYOSSZE5QDVLA
-A KUBE-SVC-4LRRYOSSZE5QDVLA ! -s 10.0.0.0/8 -d 172.16.73.164/32 -p tcp -m comment --comment "week/nginx-svc:nginx cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
$ 解释说明:
$ 第一条规则表示:将发往 nginx 服务集群 IP (172.16.73.164) 的 80 端口 TCP 流量转发到特定的服务处理链 KUBE-SVC-4LRRYOSSZE5QDVLA。
$ 第二条规则表示:对于不是来自集群内部(非 10.0.0.0/8)但目标是 nginx 服务的流量,标记它们以进行后续的地址伪装(MASQUERADE)处理【即地址转换处理】。
# 也就是说,所有的规则都指向了 KUBE-SVC-4LRRYOSSZE5QDVLA,再次过滤
[root@k8s-wn01 ~]# iptables-save | grep KUBE-SVC-4LRRYOSSZE5QDVLA
-A KUBE-SVC-4LRRYOSSZE5QDVLA -m comment --comment "week/nginx-svc:nginx -> 10.208.67.129:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-S2NHQD4JFZO6ZT3O
-A KUBE-SVC-4LRRYOSSZE5QDVLA -m comment --comment "week/nginx-svc:nginx -> 10.208.67.130:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-WCKBX4BRVWPAVTTD
-A KUBE-SVC-4LRRYOSSZE5QDVLA -m comment --comment "week/nginx-svc:nginx -> 10.42.234.135:80" -j KUBE-SEP-2ELJFQOAS5FHEUHZ
$ 第一条规则:以约33.33%的概率随机将流量转发到 IP 为 10.208.67.129、端口为 80 的 nginx 服务端点。
$ 第二条规则:在剩余流量中,以 50% 的概率随机将流量转发到 IP 为 10.208.67.130、端口为 80 的 nginx 服务端点。
$ 第三条规则:将剩余的所有流量(约33.33%)转发到 IP 为 10.42.234.135、端口为 80 的 nginx 服务端点。
$ 这三条规则一起实现了对 nginx 服务的负载均衡,将流量均匀地分配到三个不同的后端服务。
总结:Service iptables模式下的负载均衡,是靠不同的iptables规则,通过百分比的形式去进行流量分摊的。
优点:
- 性能高效:直接在内核空间处理流量,开销较小。
- 可靠性强:作为 Linux 内核的一部分,iptables 非常稳定。
- 无需额外进程:不需要单独的代理进程,减少了系统资源消耗。
- 配置灵活:可以实现复杂的网络规则和策略。
缺点:
- 规则复杂度:随着服务数量增加,iptables 规则会变得非常复杂,影响可维护性。
- 更新开销大:每次服务变更都需要刷新所有 iptables 规则,在大规模集群中可能造成明显延迟。
- 规则数量限制:大规模集群中可能达到 iptables 规则数量的上限。
- 排障困难:由于规则复杂,故障排查和问题定位较为困难。
- 缺乏高级负载均衡特性:相比其他方案,支持的负载均衡算法较少。
Ipvs模式:kube-proxy 监视 Kubernetes Service 和 EndpointSlice, 然后调用
netlink接口创建 IPVS 规则, 并定期与 Kubernetes Service 和 EndpointSlice 同步 IPVS 规则。Ipvs本身是Linux内核中的实现负载均衡的一种模块,机制,使用
netfilter函数实现。相信了解LVS负载均衡器的并不陌生。注意:若本身未检测到 IPVS 内核模块,则 kube-proxy 会退回到 iptables 代理模式运行。
修改iptables模式 --> ipvs模式:
# 编辑kube-proxy的配置文件,修改mode的模式为ipvs
kubectl edit configmap kube-proxy -n kube-system
mode: "ipvs"
# 重启所有的kube-proxy的Pod
kubectl delete pod -l k8s-app=kube-proxy -n kube-system验证:
# 还是接着上面的例子
[root@k8s-mn01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.73.164:80 rr
-> 10.42.234.135:80 Masq 1 0 1
-> 10.208.67.129:80 Masq 1 0 1
-> 10.208.67.130:80 Masq 1 0 1
# 截取nginx-svc的负载均衡规则,可以发现流量通过service的IP进入,并以rr轮询的方式转发到后端的pod IP上。
总结:Service ipvs模式下的负载均衡,是通过负载调度规则实现,通过不同的轮询算法去进行流量分摊的。
优点:
性能更高:相比 iptables,IPVS 在大规模集群中有更好的性能表现,尤其是在服务数量很多时。
- 更多的负载均衡算法:支持多种调度算法,如轮询、加权轮询、最少连接等。
- 更好的可扩展性:使用哈希表作为数据结构,规则查找的时间复杂度为O(1),不受规则数量影响。
- 连接保持能力:支持 FULLNAT 模式和连接保持,有利于应用层会话保持。
- 更新效率高:服务更新时只需要更新相关的 IPVS 规则,不需要刷新所有规则。
缺点:
- 配置复杂度增加:相比 iptables,IPVS 的配置和管理可能更复杂。
- 额外的内核依赖:需要确保 Linux 内核支持 IPVS 模块,可能需要额外的配置或升级。
- 故障排查难度增加:由于其工作在更底层,排查问题可能需要更专业的网络知识。
- 可能需要额外的内存:在某些情况下,IPVS 可能比 iptables 消耗更多的内存。
- 兼容性问题:一些旧版本的 Linux 发行版可能对 IPVS 的支持不够完善
有、无头Service
先说结论:
会被分配一个集群IP,且具备负载均衡功能的称为有头Service,也就是我们上方所说的标准Service。
不会被分配一个集群IP,且不具备负载均衡功能的称为无头Service,是Kubernetes中的一种特殊Service类型。
二者对比:
| 有头Service(标准Service) | 无头Service |
|---|---|
| 会被分配一个集群IP | 不会被分配集群IP |
| 具备负载均衡功能 | 不具备负载均衡功能 |
| 由kube-proxy处理 | kube-proxy不处理 |
| 平台提供负载均衡和路由支持 | 平台不提供负载均衡或路由支持 |
创建无头Service:
- 将
.spec.type设置为ClusterIP(这是默认值) - 将
.spec.clusterIP设置为"None"
示例YAML:
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
clusterIP: None # 这使其成为无头Service
selector:
app: my-app
ports:
- port: 80
targetPort: 8080
无头Service工作原理:
无头Service不使用虚拟IP地址和代理来配置路由和数据包转发。相反,它通过内部的DNS服务报告各个Pod的端点IP地址。这些DNS记录由集群的DNS服务(Coredns)提供。
DNS的配置方式取决于Service是否定义了选择器(即上述YAML的selector字段):
- 带选择算符的Service:
- Kubernetes控制平面创建EndpointSlice对象,自动找到匹配的Pod
- DNS查询会直接返回所有匹配Pod的IP地址
- 无选择算符的Service:
- 控制平面不创建EndpointSlice对象,即不自动查到Pod
- 如果是指向外部服务(
ExternalName类型),DNS返回那个类型的Service的名称 - 如果是手动配置的内部端点,DNS返回这些端点的IP地址
- 定义无选择算符的无头 Service 时,
port必须与targetPort匹配
简单来说,带选择算符的Service自动管理Pod,而无选择算符的服务则更灵活,可以指向任何你想要的地方,无论是集群内还是集群外。
也因此,DNS的配置方式受此影响,若是带选择算符,则DNS的配置就是那一组标签的Pod IP;若不带,则DNS的配置会根据Service的具体配置而变化。
适用场景:
无头Service特别适用于以下场景:
- 需要直接访问Pod IP的场景
- 客户端需要知道所有后端Pod的情况
- 分布式系统,如数据库集群
- 自定义负载均衡
- 服务发现
处理Pod IP变化的问题
一个常见的疑问是:既然Pod的IP会变化,为什么还要直接访问Pod的IP呢?
在分布式系统中,这种直接访问仍然是必要的。以分布式数据库系统为例:
- 新数据库节点(Pod)加入集群时,通过无头Service的DNS查询获取所有现有节点的IP。
- 新节点连接到这些IP,加入集群。
- 其他节点感知新节点的加入,更新成员列表。
- 如果某个节点的IP发生变化,集群通过内部机制检测并更新这个变化。
这个过程由数据库系统的内部服务发现机制处理,而无头Service提供了必要的DNS支持。
有/无状态服务
Service本质是暴露服务到网络上,提供访问入口的。那么针对不同的服务,可能所需要创建的Service类型(有/无头)也会不同。
服务分为:有状态服务;无状态服务。
我们以:是否需要记住连接/交互之前的信息的服务,判断是有/无状态的服务。
需要记住,则是有状态服务;不需要记住,则是无状态服务。
举个栗子:
想象你去一家咖啡店:
- 无状态服务: 每次你点单,服务员都会问你要什么,即使你刚刚才点过。他们不记得你之前的选择。
- 有状态服务: 服务员记得你之前点的内容。当你再来时,他们可能会说:"还是老样子吗?"
再举个栗子:
有状态服务会保存用户的信息和之前的交互历史。比如,在线购物网站记住你的购物车内容,即使你关闭了浏览器。
无状态服务断开连接,关闭浏览器,则用户刚刚所记录/处理的信息,都会随之清空。
有状态的服务:
数据库:例如Mysql的数据会持久化到磁盘,那么每次Mysql重启,他都能够找到上次数据保存的位置,这本身也是状态的维护。
网页的Session:也是有状态的一种体现,它能够根据Session,自动得知用户上次访问/停留的页面是什么。
无状态的服务:
静态web服务器: 每次请求都是独立的,不需要记住之前的交互。且显示的内容都是一样的,也不需要记录。
DNS(域名系统): 每次查询都是独立的,不依赖于之前的查询。
二者对比;
| 无状态服务 | 有状态服务 |
|---|---|
| 更容易水平扩展,因为可以简单地添加更多实例 | 扩展需要考虑状态同步和一致性问题 |
| 无状态服务的失败通常影响较小,容易恢复 | 有状态服务需要额外的机制来确保状态的可靠性和一致性 |
| 不需要维护复杂的状态 | 利用缓存的状态信息,提供更快的响应 |
| 设计更简单,易于理解和维护 | 可能更复杂,需要处理状态管理、同步等问题 |
在实际应用中,许多系统会综合二者来使用,以平衡各自的优势和劣势。例如:某东App可能使用无状态服务,来提供商品列表,同时使用有状态服务,来构建购物车或用户服务。
这样看来,无状态服务可以通过使用有头Service来提供,反向代理和负载均衡功能,因为毕竟不需要考虑连接状态;有状态服务可以通过使用无头Service,因为不需要,也不能使用反向代理和负载均衡,而是需要直接通过集群中DNS解析,来直接连接到每一个Pod中,保持状态的连接。
写在最后
本文整体梳理了Service相关概念,由于Service是网络层面的,还需要对容器底层,以及Pod底层访问通信的原理,可能对本文的理解会更容易些。不知不觉又是5000字了,下一篇打算再梳理一篇可观测性的文章吧,目前也是云原生的关键服务,观测性服务市面上也有许多,例如:Skywalking,Jaeger,Zipkin,OpenTelemetry等等,主说OpenTelemetry吧。
参考链接
[1] https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/#defining-a-service
[2] https://kubernetes.io/zh-cn/docs/reference/networking/virtual-ips